![]()
![]()
![]()
![]()
![]()
![]()
![]()
This chapter describes features specific to the Chinese locale in Tru64 UNIX that are not described elsewhere.
You can download up to 100 phrase definitions into the built-in memory of the VT382-D traditional Chinese terminal. You can create a phrase definition file containing the definitions and then download the file to the terminal through the serial port.
Note
The information presented in this section is not applicable to the system Phrase Utility or the dxim Phrase input method discussed in Chapter 7.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Each phrase definition file can contain up to 100 phrase definitions. You can create the file using any editor (such as vi) that allows you to edit Chinese data.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Phrase definitions have the following syntax:
DCS Pc SP v phrase-code / phrase-data ST
Table 9-1 lists the parameters.
DCS | A phrase identifier defined by Tru64 UNIX. Its hexadecimal code is 90. For the 7-bit environment, you can use ESC P (hexadecimal code 1B 50) instead. |
Pc | A parameter that controls whether the old phrase definitions in the memory should be cleared before a new one is downloaded. If Pc equals zero or is omitted, the old phrase definitions are kept. They are cleared if Pc is equal to 1. |
SP | A space character. |
v | A lowercase v. |
phrase-code | A phrase code is a string of up to 8 alphanumeric characters. Uppercase and lowercase letters are regarded as same characters. |
/ | A slash character separates a phrase code from its phrase data. |
phrase-data | A phrase containing up to 80 characters. Characters can be Chinese characters, English letters, numerals, or printable symbols. |
ST | An identifier that signals the end of the DCS statement. Its hexadecimal code is 9C. For the 7-bit environment, you can use ESC \ (hexadecimal code 1B 5C) instead. |
The following examples show phrase definition files for the 8-bit and 7-bit environments respectively:
<DCS>1 vBL/提貨單<ST>
<DCS>0 vBW/保稅倉庫<ST>
<DCS>0 vBTT/銀行電匯<ST>
<DCS>0 vCBC/中央銀行<ST>
<DCS>0 vCH/票據交換所<ST>
<DCS>0 vCL/託收<ST>
<DCS>0 vCM/佣金<ST>
<DCS>0 vCPD/運費付訖<ST>
<DCS>0 vCWO/憑票即付<ST>
<DCS>0 vFAS/船邊交貨<ST>
<DCS>0 vLC/信用狀<ST>
In this example, the second slash in each phrase definition is regarded as part of the phrase definition:
<ESC>P1
vAMBASSAD/國賓大飯店/AMBASSADOR<ESC>\
<ESC>P0 vASIA/環亞大飯店/ASIA
WORLD PLAZA<ESC>\
<ESC>P0 vBROTHER/兄弟大飯店/BROTHER<ESC>\
<ESC>P0 vCENT/世紀大飯店/CENTURY
PLAZA<ESC>\
<ESC>P0 vFORTUNA/富都大飯店/FORTUNA<ESC>\
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The procedure for transferring phrase definitions from a disk file to the terminal is called downloading. The downloaded phrases are kept in the terminal memory as long as the terminal is powered on. Consequently, a phrase definition file needs to be downloaded only once in a terminal session.
To download a phrase definition file to a terminal, display the file onto a terminal using the Tru64 UNIX cat command. You can also download phrase definitions using the Phrase Utility.
The following situations may occur during downloading:
<DCS>1 vPHONETIC/注音輸入法AT
<DCS>0 vINTERNAL/內碼輸入法<ST>
The AT at the end of the first line is incorrect. If you enter the phrase code "PHONETIC", the following string is input:
注音輸入法AT0 vINTERNAL/內碼輸入法
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The methods for sorting Chinese characters are shown in Table 9-2 and Table 9-3.
Sorting Method | Full Option Name | Short Option Name |
|---|---|---|
Internal code | Code | C |
Phonetic | Phonetic | P |
Radical | Radical | R |
Stroke | Stroke | S |
Sorting Method | Full Option Name | Short Option Name |
|---|---|---|
Qu-Wei | Quwei | Q |
Pinyin | Pinyin | P |
Radical | Radical | R |
Stroke | Stroke | S |
You can sort Chinese data using the internationalized sort utility. This utility allows you to use one sorting method by selecting the respective locale as described in Chapter 3. In some cases, you might find that using one sorting method is insufficient to meet your needs. You may need to sort your data with multiple collating sequences. For instance, many characters can have the same number of strokes and you might want to sort these characters further according to their radicals.
To sort characters according to their radicals, Tru64 UNIX provides an extended sort utility, called asort, that you can use to sort or merge files containing Chinese characters according to specified collating sequences. The asort utility has the same syntax as that of the sort utility, but it provides two additional options:
-C"collate_sequence" | Defines the collating sequences where collate_sequence is a list of identifiers or abbreviations of the collating sequences for sorting or merging a file. |
-v | Sorts Chinese data in breadth-first comparison, just like the behavior of the VMS/Hanyu or VMS/Hanzi sorting mechanism. By default, depth-first comparison is used. |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The asort utility allows you to specify multiple collating sequences. By default, Chinese data is sorted by internal code. You can specify collating sequences with the -C option so that Chinese data can be sorted using other collation methods. For example, the following command sorts DEC Hanyu data files in the order of stroke, radical, and then phonetic:
% setenv LANG zh_TW.dechanyu
% asort -C"Stroke Radical Phonetic" input.dat> output.dat
Alternatively you can enter:
% setenv LANG zh_TW.dechanyu
%
asort -C"srp" input.dat > output.dat
These commands first sort the input data file according to the number of strokes. If multiple characters have the same number of strokes, they are then sorted by radical. If multiple characters within this group start with the same radical, they will then be sorted by phonetic order.
Note
The asort utility is locale sensitive. You should first set the LANG environment variable to the required Chinese locales before using the asort utility.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
By default, the asort utility compares Chinese data according to the specified collating sequences using depth-first comparison. That is, each character in a sort field is compared using all the specified collating sequences until the collating order is resolved. When two characters have the same collating order, the next pair of characters is compared.
OpenVMS/Hanyu or Open VMS/Hanzi use a slightly different sorting mechanisms. The HSORT utility provided with OpenVMS/Hanyu sorts characters in the whole sort field using the first collating method. The second collating method applies only if the collating order of the two sorting fields are identical. This is called breadth-first comparison. If you want your sorting results to be compatible with that generated by OpenVMS/Hanyu or OpenVMS/Hanzi, you can specify the -v option:
% asort -C"srp" -v input.dat > output.dat
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The asort utility supports the sorting of user-defined characters with the collating values defined through the cedit utility. If required, the asort utility looks up the collating values from the User-Defined Character (UDC) database and sorts the data accordingly. The mechanism for sorting UDCs is totally transparent to you.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Hanyu DECterm is a VT382-D terminal emulator; Hanzi DECterm is a VT382-C terminal emulator. This section describes the Chinese features that are specific to the Hanyu and Hanzi DECterm. For details on the common internationalization features provided by DECterm, see Writing Software for the International Market.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The terminal type that DECterm emulates is sensitive to the session language.
To create a Hanyu DECterm through the Session Manager, set the session language to one of the traditional Chinese locales, for example, Chinese Taiwan, and then select DECterm from the Applications menu of Session Manager. To create a Hanzi DECterm, select one of the simplified Chinese locales, for example, Chinese China.
Alternatively, you can use the -xnllanguage qualifier to specify the terminal type of the DECterm to create. For example, you can use zh_CN.dechanzi as the value for -xnllanguage to create a Hanzi DECterm:
% /usr/bin/X11/dxterm -xnllanguage \ zh_CN.dechanzi
If you specify an unknown value for -xnllanguage, then ISO Latin-1 DECterm is assumed. If no Chinese font exists, it default to ISO Latin-1 DECterm.
The user interface language of Hanyu and Hanzi DECterm always follows the terminal type. The language is independent of the language selection.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Except for customization of NRCS character sets, all customization features applicable to the ISO Latin-1 DECterm window can also be applied to any Hanyu or Hanzi DECterm window.
Customized features can be saved and restored in the same way as in ISO Latin-1 DECterm.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
By choosing the Big Font or Little Font option from the Window... item of the Options menu you can choose either the 24 x 24 or 16 x 18 Chinese fonts.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
By choosing the General... item from the Options menu you can change the general features, such as the terminal type, for the Hanyu and Hanzi DECterm from a dialog box. You can also choose the VT382 ID from the dialog box.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
By choosing the Input Method... item from the Options menu you can select the interaction style for Hanyu and Hanzi DECterm. For example, if you want to select the Root window interaction style, you can click on the Root window button and then apply the change. If you click on the ISO Latin 1 Input button, Hanyu and Hanzi DECterm disable the input of Chinese data until another style is selected.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
By choosing the Input Method... item from the Options menu you can switch to use another input server for Hanyu and Hanzi DECterm. By default, the traditional Chinese input server is used for Hanyu DECterm, and simplified Chinese input server is used for Hanzi DECterm. To select another input server, you can click on the Other button and then enter the input server name on the input field.
For Hanyu DECterm, you can enter DECCN to switch to the simplified Chinese input server. For Hanzi DECterm, you can enter DECTW to switch to the traditional Chinese input server. For details about these input servers, see Chapter 7.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
You can use the Edit menu to copy information within or between DECterm windows. The cut-and-paste operation is enhanced to handle mixed ASCII and Chinese characters. Beyond this, conversion between traditional and simplified Chinese data is performed when data is copied between Hanyu DECterm and simplified Chinese applications, and between Hanzi DECterm and traditional Chinese applications, through the cut-and-paste or quick copying operation.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Hanyu DECterm supports CNS 11643 (first and second planes), DTSCS, and all character sets supported by the ISO Latin-1 DECterm. Hanzi DECterm supports GB2312 and all character sets supported by the ISO Latin-1 DECterm.
ISO Latin-1 DECterm uses ISO 8859-1 (Latin-1) as the default character set. You can override this setting by choosing another option from the General... item on the Options menu. For Hanyu DECterm, the default character set for 8-bit data is the Hanyu character set (CNS 11643 and DTSCS). For Hanzi DECterm, the default character set for 8-bit data is the Hanzi character set GB2312.
In general, Hanyu and Hanzi DECterm cannot display mixed accented Latin-1 characters and Chinese characters. If you want to achieve this, you can output the data together with the designated character set escape sequences.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
You can enter Chinese characters in Hanyu and Hanzi DECterm by invoking any of the Chinese input modes as described in Table 7-4.
Mixed ASCII and Chinese characters can be displayed properly in Hanyu and Hanzi DECterm without any special settings.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Chinese input server provides you the ability to input Chinese characters. If this process does not exist or terminates for some reason, one of the following messages is displayed:
You can restart the input server and then use the Reset Terminal option from the Commands menu to reconnect the Hanyu and Hanzi DECterm to the input server.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The following functions of the VT382-D and VT382-C terminal are implemented in the Hanyu and Hanzi DECterm terminal emulator respectively:
- Level 3 terminal compatibility
- ANSI-compatible control functions
- DEC Special Graphics Character Set (line drawing)
- DEC Supplemental Character Set
- DEC Technical Character Set
- ISO Latin-1 Character Set
- CNS11643-1986 and DTSCS-1990 Character Sets for VT382-D, and GB2312-80 Characters Sets for VT382-C
The following functions of the VT382-D terminal are implemented in the Hanyu DECterm terminal emulator:
A selection button is added in the Display... item under the Options menu for users to enable or disable the display of a symbol for the leading code in a four-byte EDPC character.
For details about the VT382-D terminal functions, see the VT382-D Programming Reference Manual and VT382-D User's Manual. For details about the VT382-C terminal functions, see the VT382-C Programming Reference Manual and VT382-C User's Manual.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Chapter 2 describes how Tru64 UNIX supports conversion between different codesets using the iconv utility. This utility can also be used for phrase conversion. When phrase conversion is activated, a phrase in traditional Chinese can be converted to a phrase in simplified Chinese, or the reverse. Phrase conversion does not apply to traditional Chinese encoded in Telecode, but this is the only exception.
To activate the phrase conversion option, you can define the ICONV_PHRCONV environment variable. If this environment variable is set to mark, the converted phrases are enclosed in brackets ([]) to highlight the conversion result for visual checking.
The phrase conversion databases in the /usr/share/phrdb directory are normal text files with the same file names as those of the algorithmic converters in /usr/lib/nls/loc/iconv/*. These phrase conversion databases contain entries for phrase conversion pairs.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The nroff utility has been internationalized to format text of various languages. When a Chinese document is formatted using nroff, its contents are handled according to Chinese formatting rules:
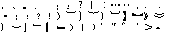
For simplified Chinese,
the no-first characters include the following:
、。ˉˇ‥〃―~∥...
,
" 〕〉》」』
〗】∶!),.:;>?]}
- Some Chinese characters cannot be placed
at the end of a text line. They are called no-last characters. For traditional
Chinese, the no-last characters include the following:
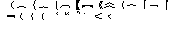
For simplified Chinese, the no-last characters include the followings:
~ ' "
〔〈《「『〖【([{
- Some English characters are handled similarly according to this rule. No-first
English characters include the following:
! ) , . : ; > ? ] )
No-last English characters include the following:
( < [
(
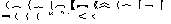
For simplified Chinese, the can-space-before characters include the following:
' " 〔〈《「『〖([{
- After a can-space-after character if it is
not placed at the end of a text line.
For traditional Chinese, the can-space-after
characters include the following:
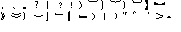
For simplified Chinese, the can-space-after characters include the followings:
、。 ' "
〕〉》」』〗】!),.>?]}
![]()
![]()
![]()
![]()
![]()
![]()
![]()