![[Compaq]](../../images/hp.gif)
![[Go to the documentation home page]](../../images/buttons/hp_bn_site_home.gif)
![[How to order documentation]](../../images/buttons/hp_bn_order_docs.gif)
![[Help on this site]](../../images/buttons/hp_bn_site_help.gif)
![[How to contact us]](../../images/buttons/hp_bn_comments.gif)
![[OpenVMS documentation]](../../images/hp_ovmsdoc_sec_head.gif)
| Document revision date: 15 July 2002 | |
|
|
|
|
|
|
| Previous | Contents | Index |
A deadlock occurs when there is a set of processes and each process is waiting to access a record that is locked by another process in the set. The program stalls because none of the processes can acquire the record that it needs to complete its task and release its locks.
The lock manager resolves the deadlock by denying one of the lock requests. When this occurs with a record lock, RMS returns an RMS$_DEADLOCK status. The RMS$_DEADLOCK status is only returned if the wait-if-locked option is selected. If your application program does its own wait and retry handling, the deadlock will occur, but the lock manager will not detect it.
The amount of time that lapses before RMS takes action on the deadlock
depends on the value specified in the DEADLOCK_WAIT system parameter.
The default value for this system parameter is 10 seconds. For further
details about how this parameter is set, see the OpenVMS System Manager's Manual.
7.2.5.1 Record Locking Options to Control Deadlock Detection
RMS uses the distributed lock manager ($ENQ system service) for record locking.
To help prevent false deadlocks, the distributed lock manager uses the following flags for lock requests.
| Flag1 | Purpose |
|---|---|
| LCK$M_NODLCKWT | When set, the lock management services do not consider this lock when trying to detect deadlock conditions. |
| LCK$M_NODLCKBLK | When set, the lock management services do not consider this lock as blocking other locks when trying to detect deadlock conditions. |
In previous releases to OpenVMS Version 7.2--1H1, RMS did not set these flags in its record lock requests.
With OpenVMS Version 7.2--1H1, you can optionally request that RMS set these flags in record lock requests by setting the corresponding options RAB$V_NODLCKWT and RAB$V_NODLCKBLK in the new RAB$W_ROP_2 field. For more information about using these options, see the flag information in the $ENQ section of the OpenVMS System Services Reference Manual: A--GETUAI.
For more information about the lock manager, see the OpenVMS System Services Reference Manual.
7.3 Local and Shared Buffering Techniques
One of the key performance factors is record buffering, that is, the
transfer of records between a storage device and an area of memory
accessible to the application program. Between the storage device and
the record buffer in the appliction program, however, is an
intermediate buffer area that RMS maintains. An intermediate buffer
area is usually associated with each process; you can also specify a
shared buffer area for a shared file.
7.3.1 Record Transfer Modes
For synchronous and asynchronous record operations, RMS provides two record transfer modes: move mode and locate mode.
In move mode, RMS copies a record from an I/O buffer into a buffer that you specify. For input operations, data is first read into the I/O buffer from a peripheral device (such as a disk), then moved to your application program buffer for processing. For output operations, you first build the record in your application program buffer; then RMS moves the record to the I/O buffer that is used to transfer the record to disk.
In locate mode, RMS allows the application program to access records in an I/O buffer by providing the address of the returned record as the internal buffer location instead of an application program buffer location (field RAB$L_RBF). Usually, this reduces program overhead because records can be processed directly within the I/O buffer. Locate mode is only available for input operations. Because it may not always be possible to use locate mode, you must supply an application program buffer for cases in which move mode must be used, even though you specify locate mode (see the OpenVMS Record Management Services Reference Manual).
Other RMS facilities allow programs to control I/O buffer space
allocation or to leave space management to RMS. The following sections
describe buffering.
7.3.2 Understanding Buffering
Your program perceives RMS record processing as the movement of records between a file and the program itself. In fact, RMS uses internal memory areas called I/O buffers to read or write blocks or buckets of data. Transparent to your program, RMS transfers blocks or buckets of a file into or from an I/O buffer. Records within the I/O buffer are then made available to the program when RMS transfers the records between the I/O buffer and the application program's record buffer.
The unit of data transfer between a file and the I/O buffers depends on the file organization. For the sequential organization, RMS reads and writes a block or series of blocks. For relative and indexed organizations, RMS reads and writes buckets.
The relationship between the application program and the I/O buffers that RMS maintains is shown in Figure 7-2. As illustrated, the application program resides in the P0 region of process address space. The RMS-maintained buffer area, together with RMS-maintained control information, resides in the P1 region.
Note that RMS normally overflows into P0 space and that the linker provides options for controlling the overflow. Note, too, that linker options are available for allocating additional buffer space in the P0 region, if needed. See the OpenVMS Linker Utility Manual for details.
Figure 7-2 RMS Buffers and the Application Program
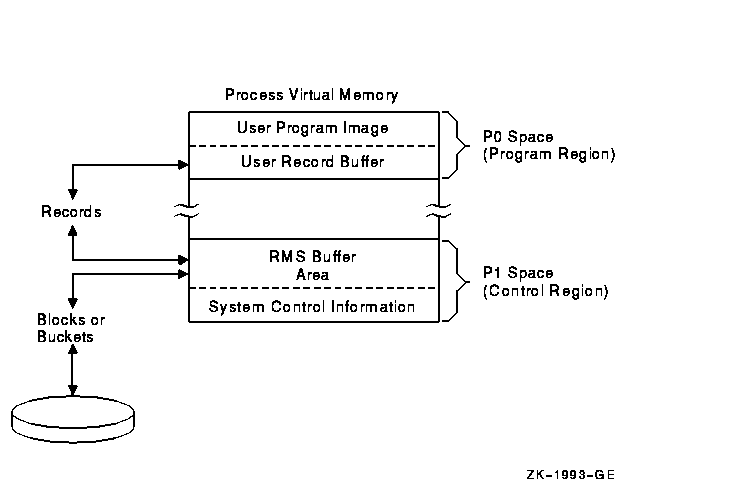
The specified record buffer contains the record to be read or written, and RMS maintains the rest of the block in application program process space in an RMS-controlled area of the program.
For optimum performance, consider the number of buffers carefully. The defaults calculated by RMS are few and may be adequate for access to small files. For example, it is not unusual to specify many buffers when processing a large indexed file, yet the default number of buffers RMS provides is only two.
The CONNECT secondary attribute MULTIBUFFER_COUNT establishes the number of local buffers, but the FILE secondary attribute GLOBAL_BUFFER_COUNT (FAB field FAB$W_GBC) specifies the number of global buffers as described in Section 7.3.6.
Often the best way to achieve optimum buffering for a particular application program is to use combinations of buffer sizes and numbers of buffers. One approach is to time each combination and measure the number of I/O operations. Then consider the amount of memory used before you choose the one that improved application program performance the most.
With buffering, the goal is to use a buffer size and number of buffers that improves application program performance without exhausting the virtual memory resources of your process or system. Keep in mind the trade-offs between file I/O performance and exhausting memory resources. The buffers used by a process are charged against the process's working set. You should avoid allocating so many buffers that the CPU spends excessive processing time paging and swapping. For performance-critical application programs, consider increasing the size of the process working set and adding additional memory.
The system manager should monitor the paging and swapping activity of the application program's process and selected other processes to avoid improving the performance of the target application program at the expense of other application programs. Have your system manager consult the Guide to OpenVMS Performance Management 1
When records are accessed sequentially, a large buffer (or buffers) should be used. Contiguous records in a file are read into memory in one or more blocks for sequential files or in buckets (multiblock units) for relative and indexed files. After the blocks or buckets are read into the buffer area provided by RMS, later access to adjacent records would access records in the same block or bucket in the buffer. This eliminates additional I/O and improves performance. When a record is needed that is not in the current buffer cache, one of the buffers is replaced by the blocks or the bucket that contains the new record.
When records in the file are repeatedly accessed, using more than one buffer can hold the previously accessed records in memory longer and eliminate an I/O operation when the program accesses the records again.
The buffers that the application program requests RMS to allocate for
its use are referred to as a buffer cache and can be
thought of as a buffer pool for your process. RMS uses buffer caches to
locate records first before attempting I/O to the target device. When
many processes share a file, the program can use a shared global buffer
cache. (See Section 7.3.6.)
7.3.3 Buffering for Sequential Files
With sequential files, the number of local buffers and the size of the local buffers can be specified at run time. You specify the number of local buffers with the FDL attribute CONNECT MULTIBUFFER_COUNT and you specify the buffer size with the FDL attribute CONNECT MULTIBLOCK_COUNT.
Sequential files provide an option that uses two buffers. One buffer holds records to be read from the disk or written to the disk. The other buffer awaits I/O completion. This is called read-ahead and write-behind processing and should be considered for sequential access to sequential files. The number of buffers (CONNECT MULTIBUFFER_COUNT) should be specified as 2. The length of the buffers used for sequential files is determined by the specified multiblock count (CONNECT MULTIBLOCK_COUNT). For sequential access to a sequential file, the optimum number of blocks per buffer depends on the record size, but a value such as 16 is usually appropriate.
To see the default buffer count for the current process, use the DCL
command SHOW RMS_DEFAULT. To set the default buffer count for the
current process, use the DCL command SET
RMS_DEFAULT/SEQUENTIAL/BUFFER_COUNT=n, where n is the number
of buffers.
7.3.4 Buffering for Relative Files
With relative files, buckets, not blocks, are the unit of transfer between the disk and memory. The bucket size is specified when the file is created, although the bucket size of an existing file can be changed by converting the file (see Chapter 10).
The bucket size is specified by the FDL attribute FILE BUCKET_SIZE (VMS RMS control block field FAB$B_BKS or XAB$B_BKZ). When choosing this value, you should consider whether or not the file is usually accessed randomly (small bucket size), sequentially (large bucket size), or both (medium bucket size), as described in Chapter 2.
You can specify the number of local buffers (CONNECT MULTIBUFFER_COUNT) at run time. The type of record access to be performed determines the best use of local buffers. The two extremes of record access are that records are processed completely randomly or completely sequentially. Also, there are cases in which records are accessed randomly but may be reaccessed (random with temporal locality), and cases in which records are accessed randomly but adjacent records are likely to be accessed (random with spatial locality).
For completely random or sequential access, a single buffer should be specified. In a processing environment in which the program processes records randomly and sometimes reaccessed records, use multiple buffers to keep the reaccessed records in the buffer cache.
When records are accessed randomly and adjacent records are apt to be accessed, you should specify a single buffer. However, if your program is processing a file with small bucket sizes, you should consider specifying more buffers. When the file is likely to be accessed by several methods, you should consider a compromise of the number of buffers and bucket sizes.
When adding records to a relative file, consider choosing the deferred-write option (FDL attribute FILE DEFERRED_WRITE; FAB$L_FOP field FAB$V_DFW). With this option, the buffer (memory-resident bucket) into which the records have been moved is not written to disk until the buffer is needed for other purposes or until the file is closed. Note that if you use the deferred-write option, there is a risk that data may be lost if a system crash occurs before the records are written to disk.
To see the current process-default buffer count, use the DCL command
SHOW RMS_DEFAULT. To set the process-default buffer count, use the DCL
command SET RMS_DEFAULT/RELATIVE/BUFFER_COUNT=n, where n is
the number of buffers.
7.3.5 Buffering for Indexed Files
With indexed files, buckets (not blocks) are the units of transfer between the disk and memory. The bucket size is specified when the file is created, although the bucket size of an existing file can be changed by converting the file (see Chapter 10).
The bucket size is specified by the FDL attribute FILE BUCKET_SIZE (VMS RMS control block field FAB$B_BKS or XAB$B_BKZ), as described in Chapter 2.
When accessing indexed files, it is important to remember that the index portion of the file must be read by RMS to locate the desired record. The algorithm used by RMS places a higher priority for the higher-level buckets of the index in the buffer cache. Thus, the highest levels of the index remain in the buffer cache, while the buffers that may have contained the actual data buckets and the lower-level index buckets are reused to contain other buckets. That is, the buffers that are reused first contain either data or lower-level index buckets, which are the first to be discarded from the buffer cache.
When accessing indexed files, the number of local buffers (CONNECT MULTIBUFFER_COUNT) is specified at run time and recommended values can vary greatly for different application programs. When records are processed randomly, use as many buffers as your process working set can support to cache additional index buckets. When records are accessed sequentially, even after locating the first record randomly, use a small multibuffer count, such as the default of 2 buffers.
Many application programs access files using a mixture of completely random and completely sequential processing. For such application programs, a compromise of the above number of buffers is recommended.
When adding records to an indexed file, consider choosing the deferred-write option (FDL attribute FILE DEFERRED_WRITE; FAB$L_FOP field FAB$V_DFW). With the deferred-write option, the buffer into which the records have been moved is not written to disk until the buffer is needed for other purposes or until the file is closed. This option, however, may cause records to be lost if a system crash should occur before the records are written to disk.
To see the current process-default buffer count, use the DCL command
SHOW RMS_DEFAULT. To set the process-default buffer count, use the DCL
command SET RMS_DEFAULT/INDEXED/BUFFER_COUNT=n, where n is the
number of buffers.
7.3.6 Using Global Buffers for Shared Files
Two types of buffer caches are available using RMS: local and global. Local buffers reside within process (program) memory space and are not shared among processes, even if several processes access the same file and read the same records. Global buffers, which are designed for application programs that access the same files and perhaps the same records, do not reside in process memory space.
If several processes share a file, you should specify that the file uses global buffers. A global buffer is an I/O buffer that two or more processes can access in conjunction with file sharing. If two or more processes request the same information from a file, each process can use the global buffers instead of allocating its own process-local buffers. Figure 7-3 illustrates the use of global buffers.
Figure 7-3 Using Global Buffers for a Shared File
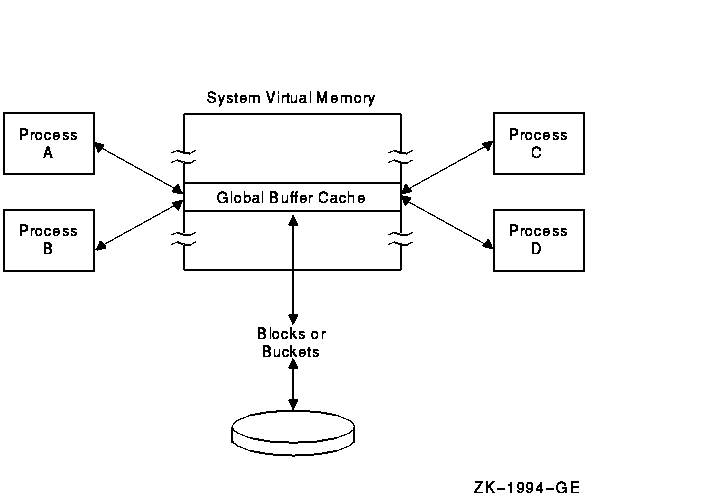
Unlike local buffers, global buffers can be accessed by multiple processes accessing the same file. When a record requested by one process is located in a global buffer, the record can be transferred directly from the global buffer to the program, eliminating an I/O read operation. Note that if the previous accessor modified the record, RMS writes the buffer to disk before returning the record to the new accessor. This ensures that the modified bucket in memory matches its counterpart on the disk.
There are two situations in which global buffers cannot be used for shared files. When a process permanent file is being accessed, RMS does not use global buffers (no error is returned). When an image is linked using the LINK option keyword IOSEGMENT=NOP0BUFS (rarely used), RMS does not use global buffers.
Even if global buffers are used, a minimal number of local buffers should be requested, because, under certain circumstances, RMS may need to use local buffers. When attempting to access a record, RMS looks first in the global buffer cache for the record before looking in the local buffers; if the record is still not found, an I/O operation occurs. When using the deferred-write option with global buffering enabled, the number of buckets that can be buffered without I/O is equal to the number of local buffers; thus, the use of more than the minimum number of local buffers should be considered.
You can specify the number of global buffers two ways: by using a preset file default or by having the first process that accesses the file specify the value at run time. To set the file default (maintained in the file header), use the DCL command SET FILE/GLOBAL_BUFFERS=n where n is the number of buffers.
To set the global buffer value at run time, the first process to connect to the file with the FILE GLOBAL_BUFFER_COUNT attribute (FAB field FAB$W_GBC) greater than 0 can set this value. The default value returned in the FAB$W_GBC field following an Open (or Create) service may be altered if unacceptable before invoking the Connect service. When a previous or subsequent application program attempts to open and connect to the file, the global buffer count determines whether or not that process uses global buffers. If the value is 0, that process uses only local buffers; if the value is greater than 0, that process uses global buffers along with other processes. Refer to the OpenVMS Record Management Services Reference Manual for additional information on the use of the FAB$W_GBC field and Connect service. An example of a routine that sets the global buffer count after opening a file is provided in Example 5-2.
To request that the global buffer cache be read-only, specify SHARING GET and SHARING MULTISTREAMING attributes (FAB$B_SHR field FAB$V_SHRGET and FAB$V_MSE).
When modifying an application program to use global buffers, consider using more global buffers and slightly larger bucket sizes if records are processed randomly. For application programs with many users, consider allocating a number of global buffers equal to the number of local buffers used previously, multiplied by number of users (if resources permit):
|
No. Global Buffers = No. Local Buffers x Average No. Users |
When using an indexed file, if the index structure is small and the number of users is many, consider allocating enough global buffers to keep the entire index structure in memory.
For shared sequential file operations, the first accessor of the file
uses the multiblock count value to establish the global buffer size for
all subsequent accessors.
7.3.6.1 Enhancing Global Buffer Performance
OpenVMS includes enhancements that improve RMS global buffer performance. These features are greater scalability, greater concurrent access to the global section, and read-mode bucket locking for shared access to global buffers.
RMS implements an algorithm for global buffer management that dramatically improves scalability. The performance associated with the previous algorithm effectively limited the maximum number of global buffers on large, shared files. With this change, you may increase the number of global buffers on these files to the full limit of 32,767 to fully exploit large memory systems.
RMS synchronizes access to the global section that is used for RMS global buffers by using inline atomic instruction sequences rather than distributive locking. This change allows more concurrent access to the section, particularly on symmetric multiprocessing machines (SMP).
Greater scalability benefits those who wish to use very large global buffer counts. Concurrent access to the global section helps any application using global buffers where contention on the global section itself is a bottleneck.
By increasing the number of global buffers on specific files, you may need to increase the size of some of the system resources. In particular, you may need to increase the sysgen parameters GBLPAGES, GBLPAGFILE, or GBLSECTIONS. In addition, you may need to increase the process working set size and the page file quota. |
Read-Mode Bucket Locking (Alpha Only)
RMS reduces locking for shared access to global buffers and improves performance with its implementation of read-mode global bucket locking, which has the following functionality:
This functionality applies to read operations (using the $GET and $FIND services) for all three file organizations: sequential, relative, and indexed. It also applies to a write operation (using the $PUT service) for the read accesses used for index buckets the first time through an index tree for the write.
You do not need to change existing applications to implement the read-only global bucket locks. However, global buffers must be set on a data file to take advantage of the enhancement. Use the following DCL command, where n is the number of buffers:
$ SET FILE/GLOBAL_BUFFER=n <filename> |
For information about specifying the number of buffers, refer to the OpenVMS DCL Dictionary. For general information about using global buffers, refer to the Guide to OpenVMS File Applications.
In a mixed cluster environment where there may be high contention for specific buckets, the Alpha nodes that are using read-mode global bucket locking may dominate accesses to write-shared files, thereby preventing timely access by other nodes.
With the /CONTENTION_POLICY=keyword qualifier to the SET RMS_DEFAULT command, you can specify the level of locking fairness at either the process or system level for environments that experience high contention conditions.
For more information about using the /CONTENTION_POLICY=keyword qualifier, refer to the OpenVMS DCL Dictionary.
1 This manual has been archived but is available on the OpenVMS Documentation CD-ROM. A printed book can be ordered by calling 800-282-6672. For information about the resources needed for file applications, refer to Section 1.8. |
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 4506PRO_022.HTML | ||