![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Tru64 UNIX operating system software supports the following character sets that are relevant to the Korean language:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
This character set was published on January 6, 1993 and was formerly called KSC5636-1989 (published on April 22, 1989). The character set is sometimes referred to as KS-Roman. KSC5636-1993 is the Korean analog to ASCII and ISO 646 with the exception of the ASCII backslash (0x5C), which is represented as a Won symbol under KSC5636.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
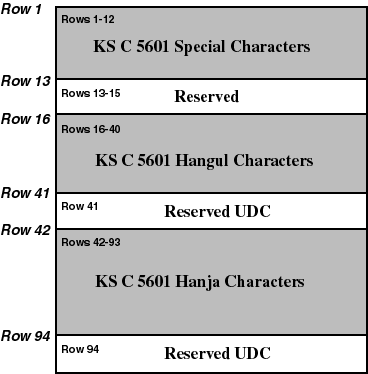
This basic Korean character set standard enumerates 8,224 characters, 4,888 of which are Hanja, and 2,350 of which are precombined Hangul. The Hanja and Hangul blocks are arranged phonetically. The standard name has recently been changed to KS X 1001:1992; however, the more well-known name, KSC, is used throughout this book. The character set is composed of the following:
Rows 41 and 94 are designated for user-defined characters.
The KSC5601-1992 character set is similar to the obsolete KSC5601-1987 character set; however, KSC5601-1992 provides more material in annexes.
Note that there are 4,888 Hanja characters in the Hanja block (Rows 42 through 93), but not all characters are unique. The Hanja block is arranged phonetically and, in some cases, the same Hanja character has more than one application. In those cases, the Hanja is duplicated (sometimes more than once) in the same character set. There are 268 such cases of duplicate Hanja characters in KSC5601-1992, therefore it contains 4,620 unique Hanja characters.
Korean Hangul characters are typically encoded in precombined form where 2 or 3 Hangul elements bound into a single character. The KSC5601-1992 character set enumerates 2,350 such precombined forms. While this number is sufficient for most purposes, it does not account for the total number of possible permutations. The encoding system that encodes all possible precombined Hangul characters is known as johab encoding (also known as "two-byte combination code" because the Korean word "johab" means "combine") and is described in Annex 3 of the KSC5601-1992 standard. This encoding is similar to encoding all possible three-letter words in English; while all combinations are possible, only a fraction represent real words.
Precombined Hangul can be composed of 19 initial, 21 medial, and 27 final Hangul elements (28 characters, if you count the placeholder). This provides a maximum of 11,172 precombined Hangul characters. Of these 67 Hangul elements, 51 are unique (some can occur in different positions). Each of these positions are encoded using five bits each (five bits can encode up to 32 unique objects). The encoding array has the following characteristics:
The initial and final elements are consonants, and the medial elements are vowels. This encoding must be treated as a 16-bit entity because the bit array of the medial Hangul element spans the first and second byte.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Unicode Standard, Version 3.0 specifies a universal character set (UCS) that contains definitions for 49,194 characters and also includes a Private Use Area for vendor-defined or user-defined characters. The main features of this character set are:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The ISO/IEC 10646 standard, which is specified in Information Technology-Universal Multiple-Octet Coded Character Set, ISO/IEC 10646, allows characters to be specified as either 32-bit units or like Unicode, as 16-bit units. In their 32-bit form, the 16-bit character values in Unicode are zero-extended.
![]()
![]()
![]()
![]()
![]()
![]()
![]()